Artikel KPKNL Mamuju

Seri Artikel DDDM KPKNL Mamuju: Data Outlier Dalam Data Mining
Ida Kade Sukesa
Rabu, 07 September 2022 |
4466 kali
Ditulis
oleh: Helvita Dorojatun (Kepala KPKNL Mamuju)
(Tulisan ini merupakan artikel ketiga dari seri Artikel DATA DRIVEN DECISION MAKING, KPKNL MAMUJU untuk KEMENKEU)
Data yang digunakan dalam melakukan pengolahan data sebaiknya
berdistribusi normal dan terbebas dari data outlier. Hal ini dikarenakan tujuan dari pengolahan
data adalah untuk mendapatkan pola yang kuat yang dapat digunakan dalam
pengambilan keputusan. Selain dapat menghasilkan pola yang bias, data outlier
yang tidak di-treatment dengan baik akan menyebabkan diperlukannya
jumlah iterasi yang lebih banyak dalam suatu permodelan.
Data outlier terdiri dari dua jenis yaitu outlier
univariat dan outlier multivariat. Diskusi tentang outlier univariat akan
mengacu pada outlier yang disebabkan oleh nilai ekstrem pada dependent variable (gambar 1) atau independent variable. Sedangkan outlier multivariat
lebih banyak mengacu pada anomali nilai residual keseluruhan independent
variable (gambar 2).
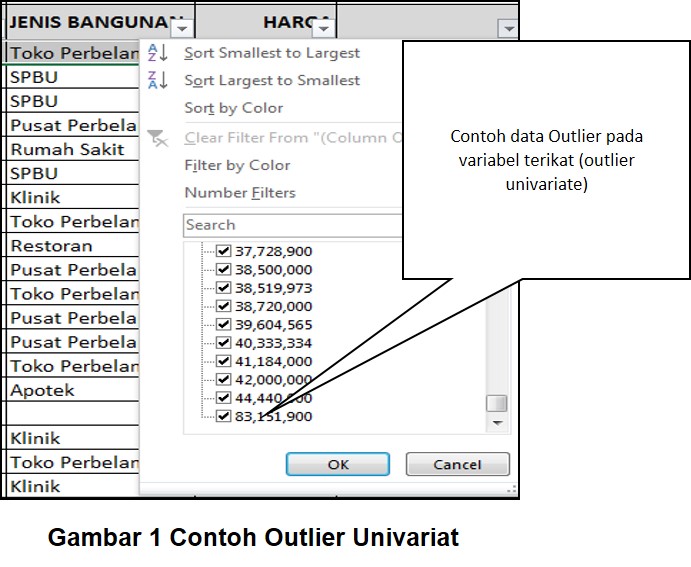

Deteksi mengenai data outlier tidak hanya penting bagi
data mining untuk role prediction dan forecasting, namun juga
sangat berpengaruh untuk olah data dengan tujuan lain semisal clustering.
Data outlier akan menyebabkan nilai Davies Boudin indeks terkecil berada pada
jumlah klaster yang banyak. Nilai
Davies Boudin indeks mencerminkan kedekatan akumulasi kumpulan data pada satu
klaster terhadap pusat (centroid)
dari klaster yang diikuti. Begitu berpengaruhnya data outlier pada
penelitian yang memiliki tujuan menggeneralisir menjadikan hampir semua
aplikasi pengolahan data memiliki tools
untuk mendeteksi permasalahan ini (gambar 3). Berikut ini disajikan beberapa tools yang dapat digunakan untuk mendeteksi data outlier.
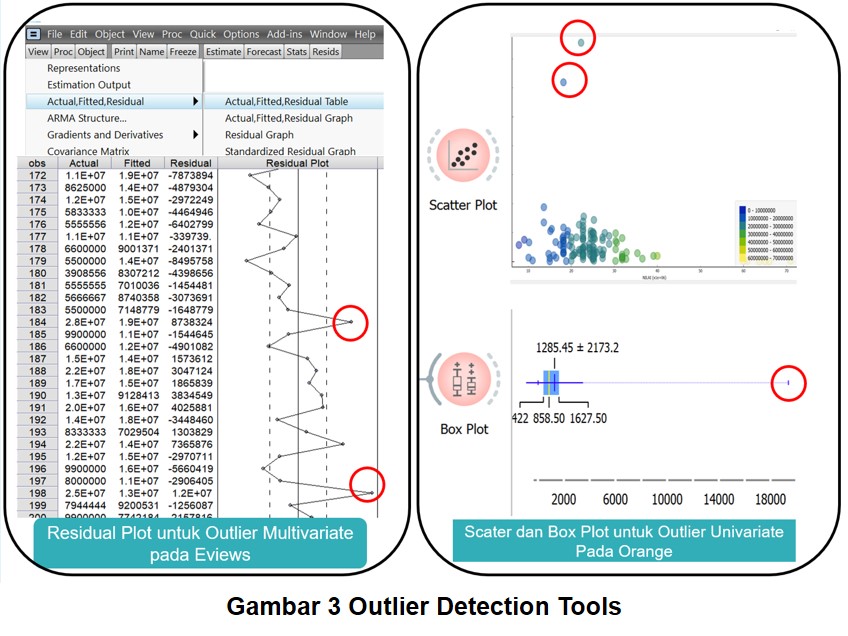
Apakah semua data yang berbeda dari kumpulan data adalah outlier?
Mungkin iya jika data yang berbeda jauh dari kumpulan data
adalah outlier, tapi secara keilmuan, outlier dapat ditentukan paling umum dengan
dua teknik yaitu persentil dan interkuartil. Teknik persentil cukup
sederhana yaitu dengan memotong data yang paling tinggi dan paling rendah
dengan cut off tertentu misalnya 1%, sedangkan Teknik Interkuartil
dilakukan dengan membagi terlebih dahulu kumpulan data dalam 4 kuartil
( Q1 sampai dengan Q4) lalu data yang
berjarak 1.5 kali dari Q1 dan Q3 (disebut juga nilai interquartil
range) dapat
didefinisikan mejadi outlier.
How to deal
with outliers in data?
Data outlier tidak harus dibuang dalam proses pengolahan data.
Terdapat beberapa langkah yang dapat ditempuh dalam upaya kita berdamai dengan
data outlier yaitu sebagai berikut:
1. Memperbaiki cara pengumpulan data perlu dilakukan pada data primer ketika terjadi
inkonsistensi yang parah. Perbaikan cara pengumpulan data dilakukan dengan
menggunakan default pada aplikasi
pengumpul data dan juga mengembangkan petunjuk pengumpulan data baik berupa
buku maupun video pendek. Inkonsistensi pada cara pengumpulan data primer juga
menjadi indikasi bahwa definisi data kurang spesifik sehingga dapat menyebabkan
interpretasi ganda.
2. Melakukan preprocessing melalui transformasi data sangat baik jika kita
bekerja dengan variable yang tidak sebanding. Variabel yang memiliki jumlah
digit berbeda jauh dan di olah dengan algoritma yang menggunakan formula
Ecludian akan sangat dipengaruhi oleh variabel dengan jumlah digit yang paling
banyak. Hal inilah yang menyebabkan perlu dilakukan transformasi data untuk
menghasilkan data yang sebanding pada variabel yang jamak. Dua cara transformasi data
yang utama adalah melalui teknik proporsi dan persentase. Sebagai contoh
berikut disajikan gambar hasil data mining metode clustering yang
menggunakan algoritma K Means, sebelum dan sesudah langkah preprocessing
(Gambar 4).
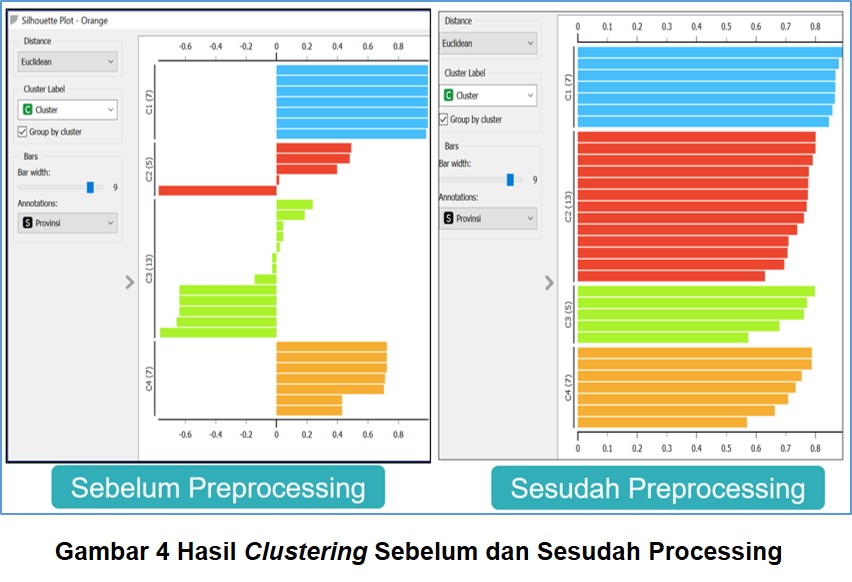
3. Mendefinisikan ulang suatu variable pada pengumpulan data primer seringkali dapat
menyelesaikan permasalahan data outlier dalam jumlah banyak dengan baik. Data outlier
seringkali tercipta dari desain penelitian awal berupa penentuan variabel yang general. Sebagai
contoh apabila kita menggunakan variabel kawasan peruntukan tanah
secara umum, maka variabel yang umum terbentuk bila menggunakan hierarki
II adalah: 1) komersial; 2) perumahan; dan 3) pemerintahan. Kemudian apabila terdapat outlier dalam
kumpulan data dalam zona peruntukan tanah perumahan, maka kemungkinan kita
perlu mendefinisikan lebih detil hingga tingkat zona hierarki III atau hierarki IV sebagaimana gambar 5 di bawah ini.
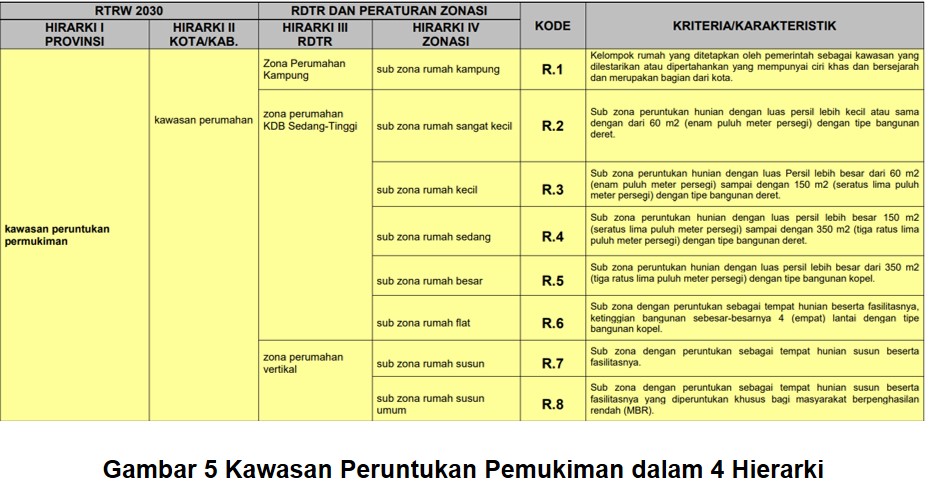
4. Langkah terakhir yang dapat dipilih adalah tidak
menggunakan data outlier
tersebut. Apabila outlier pada data merupakan hal yang alami maka kemungkinan untuk tidak menggunakan data
tersebut bisa diambil. Semisal data lokasi sewa ATM Bank terdiri dari variabel
lebar jalan dengan range 6 sampai
dengan 12 meter. Kemudian terdapat lokasi ATM yang terletak di Jalan yang
sangat lebar semisal 30 meter, maka data ini perlu tidak digunakan karena secara
alami merupakan outlier.
Referensi:
EViews
12 User’s Guide II
https://dcktrp.jakarta.go.id/Tabel_Zonasi.pdf
(jakarta.go.id)
https://orangedatamining.com/search/?q=outlier
| Disclaimer |
|---|
| Tulisan ini adalah pendapat pribadi dan tidak mencerminkan kebijakan institusi di mana penulis bekerja. |
