Jum'at, 03 Maret 2023 | 2689 kali




Ditulis oleh: Helvita Dorojatun (Kepala KPKNL Mamuju)
(Tulisan ini merupakan artikel kelima
dari seri artikel Data Driven Decision Making (DDDM) KPKNL Mamuju untuk
Kemenkeu)
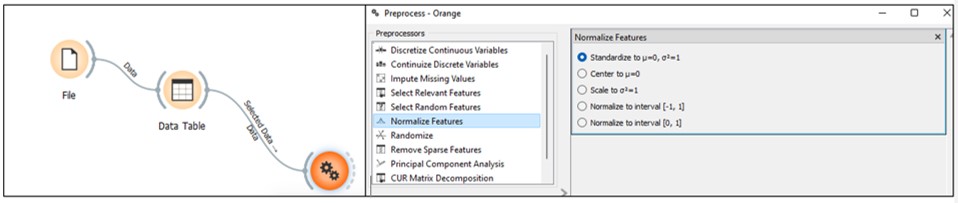
Para penggiat data analitik sering kali harus berhadapan
dengan data yang memiliki skala pengukuran sangat bervariasi. Perbedaan skala tersebut
sangat berpengaruh terhadap hasil. Lalu treatment apa yang dapat dilakukan
untuk memperoleh hasil yang tidak bias? Normalisasi dan standardisasi adalah
salah satu langkah yang dapat ditempuh untuk menghasilkan olah data terbaik.
Normalisasi adalah teknik perubahan skala pada data yang
memiliki dimensi berbeda-beda kedalam skala yang seragam yaitu diantara 0 – 1.
Mengapa normalisasi diperlukan? Karena satu set data bisa berisi berbagai macam
variasi skala pengukuran, sehingga tanpa adanya normalisasi hasil analisis
dapat dipengaruhi oleh variabel yang memiliki skala pengukuran paling besar.
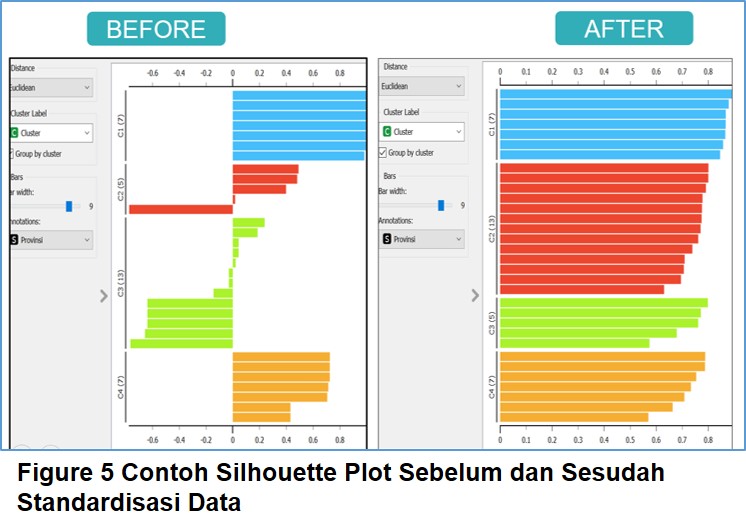
Pengaruh tersebut sangat terasa untuk pengolahan data terutama dengan teknik clustering.
Metode normalisasi data pertama yaitu simple
feature scaling.
Formula yang digunakan sangat sederhana yaitu membagi setiap nilai dengan nilai
maksimum pada fitur tersebut. Cara ini akan menghasilkan nilai baru hasil
normalisasi yang berkisar antara 0 dan 1.
Metode normalisasi min-max menggunakan nilai maksimum dan minimum untuk mendapatkan
hasil normalisasi berupa nilai baru antara 0 sampai 1. Cara kerjanya setiap
nilai pada sebuah fitur dikurangi dengan nilai minimum fitur tersebut, kemudian
dibagi dengan rentang nilai atau nilai maksimum dikurangi nilai minimum dari
fitur tersebut.
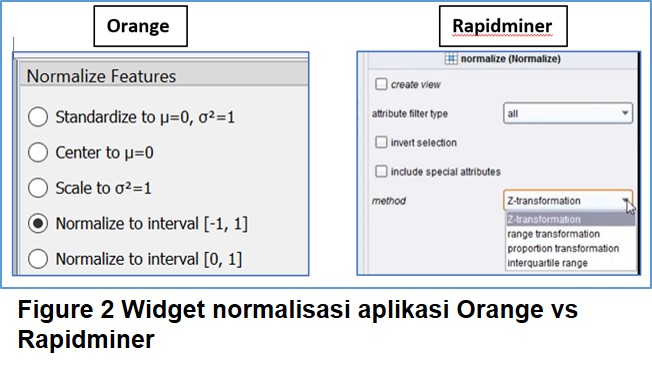
Metode normalisasi Z-score atau disebut juga standard
score menggunakan
formula dimana masing-masing nilai pada fitur dikurangi dengan miu (µ) yang
merupakan nilai rata-rata fitur, kemudian dibagi dengan sigma (σ) yang
merupakan standar deviasi. Cara ini akan menghasilkan nilai baru hasil
normalisasi yang berkisar di angka 0.

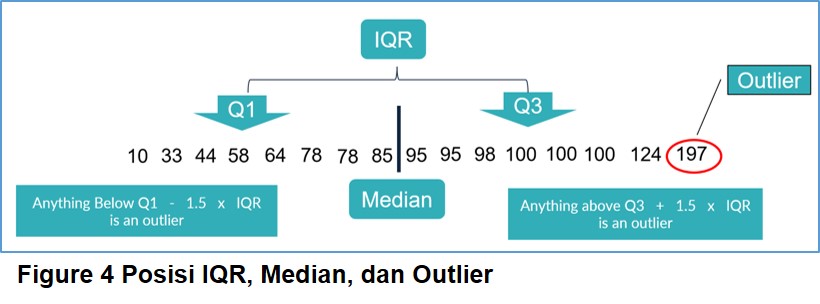
Metode normalisasi interquartile range ini ditujukan untuk mengabaikan data
Outlier [2] [3]. Hal ini dapat diamati dari formula yang digunakan yaitu: Nilai
Median/ IQR (Interquartile Range). Dimana outlier
dapat didefinisikan secara matematis sebagai data yang berada dibawah Q1 − 1.5
IQR atau di atas Q3 + 1.5 IQR. Teknik ini oleh beberapa praktisi dipisahkan
dari kelompok metode normalisasi dan disebut Robust Scaler.
Standardisasi data adalah tehnik lain dalam melakukan
perubahan skala. Teknik standardisasi dianggap paling sesuai ketika distribusi
data menujukan lonceng Gaus dan teknik ini sama sekali tidak mengubah pola
distribusi data karena miu (µ) atau nilai rata rata tetap dipertahankan di
tengah Lonceng Gaus. Sekilas teknik ini sangat mirip dengan teknik normalisasi
Z score bedanya adalah miu (µ) atau nilai rata rata diseting
sama dengan 0 (terpusat) dan standar deviasi dibatasi sama dengan 1.
Standardisasi merupakan teknik matematis untuk mendudukan
data pada rentang nilai yang relative satu frekuensi. Standardisasi umum
digunakan untuk kumpulan data yang tidak terdistribusi normal dan/atau terdapat
outlier, sehingga data scientist tetap dapat mengetahui kondisi data sebelum
diolah. Standarisasi tidak memiliki jangkauan nilai sebagaimana normalisasi
yang memiliki nilai 0–1.
Mispersepsi
Teknik normalisasi dan standardisasi tidak digunakan untuk mengatasi data outlier. Ketika data outlier masuk dalam proses normalisasi atau standardisasi maka posisi data tersebut tetap sebagai pencilan tapi skalanya saja yang berbeda. Beberapa praktisi menyarankan menggunakan teknik transformasi untuk mengobati data outlier, namun saya belum melakukan studi lebih lanjut mengenai hal ini.
Referensi:
1.
https://datacatalog.worldbank.org/search/dataset/0037801/Private-Participation-in-Renewable-Energy
2.
https://docs.rapidminer.com/latest/studio/operators/cleansing/normalization/normalize.html
3.
Data normalization with Pandas and
Scikit-Learn | by Amanda Iglesias Moreno | Towards Data Science




