Artikel KPKNL Mamuju
Seri Artikel DDDM KPKNL Mamuju: Peran Regresi Linier dalam Prediksi Nilai
Ida Kade Sukesa
Kamis, 28 Juli 2022 |
1856 kali
Ditulis oleh: Helvita Dorojatun (Kepala KPKNL Mamuju)
(Tulisan ini merupakan artikel kedua dari seri Artikel DATA DRIVEN DECISION MAKING, KPKNL MAMUJU untuk KEMENKEU)
Regresi
Linear
Regresi adalah
algoritma yang digunakan untuk memprediksi dengan berdasar pada hubungan antara
dependent variable dengan independent variable. Selain memprediksi,
regresi juga dapat memberikan informasi seberapa kuat independent variable mempengaruhi dependent variable, contohnya seberapa
besar pengaruh jarak dari Central Business District terhadap harga
sebuah properti.
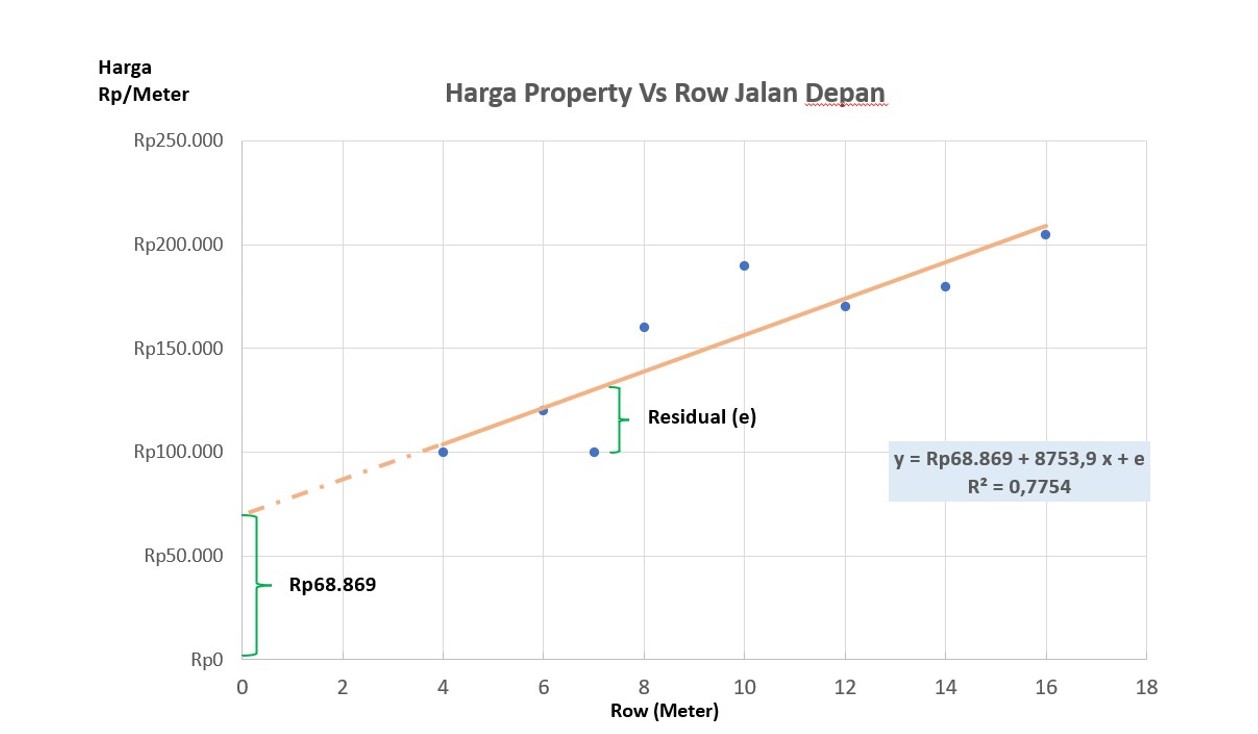
Regresi dibentuk dengan menarik garis yang melewati kumpulan data training, dan mengukur besarnya intercept (titik potong) dan kemiringan garis tersebut. Metode yang umum dipakai adalah Least Square Method. Least Square Method dilakukan dengan dengan mencari garis yang memiliki jumlah nilai residual (e) yang dikuadratkan paling kecil. Dalam mempermudah penjelasan ini disampaikan gambar deskripsi di bawah ini.
Regresi Parametrik yang banyak digunakan adalah linear
regression dan logistic regression. Linear regression digunakan untuk
menghasilkan prediksi nilai, sedangkan logistic regression memiliki kekuatan
dalam memprediksi kemungkinan terjadinya suatu kejadian. Linear regression dibentuk dari dependent variable yang terdiri dari empat jenis data yaitu
nominal, ordinal, interval,
dan ratio, sedangkan independent variable paling banyak diukur dalam bentuk interval
dan rasio (Gujarati and Porter, 2012; 3-4).
Berbeda dengan linear
regression, independent variable
untuk logistic regression umumnya menggunakan ordinal dan nominal.
Implementasi Regresi dalam Prediksi Nilai
Model regresi telah
digunakan untuk penilaian masal oleh penilai pajak properti selama bertahun-tahun.
Salah satu alasan kenapa model digunakan adalah pemodelan regresi efisien dalam
penggunaan sumber daya daripada melakukan penilaian tradisional (Appraisal
Institute, 2013; 296). Adair dan Mc Greal bahkan telah menyampaikan penggunaan analisis multiple
regression dalam penilaian properti di Amerika
Serikat dan Inggris pada tahun 1988. Model regresi pada penilaian properti umum
punya kekuatan dalam mengukur pengaruh eksternal terhadap nilai seperti
pengaruh jarak dari jalan, jarak dari pusat keramaian, dan lainnya. Penggunaan
regresi linear dalam penilaian juga telah diaplikasikan dalam penilaian Barang
Milik Negara untuk penempatan mesin ATM sejak tahun 2019 oleh penilai
pemerintah di DJKN.
Tak hanya untuk
kepentingan penilaian properti, analisis regresi juga bisa digunakan dalam penilaian bisnis.
Jordan D. T. (2007) menyampaikan bahwa terdapat beberapa hal yang menjadikan analisis
regresi dapat lebih diandalkan dibanding ratio
analysis yaitu: 1) dapat menunjukan hubungan antara nilai objek bisnis
dengan beberapa variable secara langsung; 2) dapat menjelaskan kekuatan variable
penjelas melalui skor R2; 3) dapat mengetahui variabel yang paling
berpengaruh melalui skor p value; dan 4) dapat menunjukan besarnya standard
error. Sebagai contoh Brostrom dan Larson (2015) menggunakan Enterprise
Value sebagai dependent variable,
dan sebagai independent variable digunakan
data kuantitatif yaitu: Earning Before
Interest, Depreciation & Amortization, dan Cost (Revenue-EBITDA),
serta variable Independent kualitatif berupa Daerah Asal Perusahaan, Ukuran
Perusahaan (Small and Large Enterprise), serta variable Tahun
dari 2005 sd. 2014 dalam bentuk dummy variable.
Tantangan Uji Asumsi Klasik Dan Pemecahannya
Jumlah Data
Model regresi
linier sederhana dapat digunakan untuk mengestimasi pengaruh karakteristik
tertentu dengan keandalan statistik yang signifikan ketika pasokan data sangat
memadai (Appraisal Institute, 2013; 275). Selain itu ukuran kecukupan data juga
harus mempertimbangkan derajat kebebasan yaitu, hubungan antara jumlah data dan
jumlah independent variabel dalam model, dimana ketika jumlah data yang
dimiliki mendekati jumlah independent variable maka model yang dibentuk
dapat "overfitted" dan
tidak mewakili jumlah populasi.
Normalitas
Data yang digunakan
dalam melakukan pengolahan data haruslah ber-distribusi normal, kecuali jika penelitian yang akan
dilakukan memang ingin mengobservasi hal tersebut. Distribusi normal yang
dimaksud disini adalah nilai dari error
term-nya. Hal ini dikarenakan tujuan dari
pengolahan data adalah untuk mendapatkan pola yang kuat.
Autokorelasi
Autokorelasi adalah
saat dimana terjadi korelasi antara error/residual. Hal ini secara alami
paling banyak terjadi pada data time series (Gujarati and Porter, 2012; 5).
Masalah ini secara matematis dapat menyebabkan estimasi menjadi over karena standard error akan cenderung lebih
kecil daripada seharusnya.
Multikolineritas
Multikolineritas secara
bebas dan romantic dapat dideskripsikan dengan kalimat, “when two (or more) variables melted into one another”.
Hubungan multikolineritas yang exact antara dua independent variable sangat jarang terjadi apabila pengambilan dan
pengolahan data telah di desain dengan benar. Salah satu desain pengolahan data
yang benar adalah sebagaimana yang disampaikan oleh Gujarati dan Porter (2010;
358) yaitu Jumlah setiap jenis independent
variable dummy di kurangi 1. Kesalahan
dalam desain pengambilan data yang dapat menyebabkan multikolineritas, misalnya dengan memasukan independent variable berupa tingkat
keamanan dan jumlah tenaga keamanan secara bersamaan dimana kedua variable tersebut saling berhubungan.
Permasalahan
Multikolineritas pada regresi untuk memprediksi nilai suatu property menurut
Kenneth Luhst (1997:154) sedikitnya dapat menyebabkan: 1) terjadinya perbedaan
antara hasil regresi (arah pengaruh) dengan common sense atau teory yang
berlaku pada objek tersebut; dan 2) variabel yang secara teori paling berpengaruh
terhadap nilai misalnya lokasi menjadi terlihat tidak signifikan karena adanya sharing
dengan variable independen yang berhubungan.
Heterokedastisitas
Heterokedastisitas
adalah saat dimana varian residual tidak konstan. Permasalahan ini adalah hal
yang alami untuk data-data primer yang memiliki jenis beragam atau heterogen.
Data sewa properti adalah salah satunya. Hal ini karena properti memiliki sifat
yang unik yang berarti tidak ada satupun properti yang persis sama. Selain keragaman data heterokedastisitas
juga umum terbentuk pada data cross-sectional.
Beberapa hal yang
perlu diperhatikan dalam menentukan variable dalam prediksi dengan data mining:
1. Regresi tidak dapat menentukan sebab dan akibat hubungan
antara independent
variable dan dependent variable (Luhst, 1997:146). Hal inilah yang seringkali menjebak peneliti
pada penomena hubungan palsu (spurious
relationship)
antara dependent variable dan independent variable yang sebenarnya
hanya kebetulan. Agar terlepas dari jebakan tersebut sebaiknya dalam menentukan
Independent variable, peneliti
berpedoman pada: a) teori yang sudah mature; b) studi literatur/riset
terdahulu; dan c) pernyataan dari pelaku pasar.
2. Hubungan antara dependent
variable dan independent variable
sebaiknya diuji terlebih dahulu dengan menggunakan scatter diagram
(Luhst, 1997:141). Hal ini untuk menentukan apakah hubungan tersebut linear,
nonlinear atau tidak memiliki hubungan. Saat ini pada orange data mining
telah tersedia widget correlation
guna menguji korelasi tersebut.
3. Penambahan Independent Variable harus melihat pada Inflasi buatan yaitu gejala ketika variabel dependent baru yang ditambahkan menaikan nilai koefisien determinasi meskipun sebenarnya tidak berhubungan dengan variabel terikat (lihat Robey. dkk, 2019: 101). Sebagai contoh: Model A yang memiliki dua variabel independent memiliki R² 0,86 dan R² yang telah disesuaikan (Adjusted R2) 0,85. Ketika variabel Independent ketiga ditambahkan ke model A, R² meningkat menjadi 0,88 namun R² yang disesuaikan berkurang menjadi 0,83, inilah yang disebut sebagai peningkatan R² secara artifisial.
4. Perhatikan dua outliers.
Dua jenis outlier
yang dimaksud disini adalah univariate
outlier dan multivariate outlier. Univariat
outlier adalah outlier yang disebabkan hanya oleh anomali pada dependent variable. Sedangkan multivariat outlier adalah outlier pada kalkulasi keseluruhan Independent variable. Outlier
dapat diprediksi pada aplikasi eviews dengan mengacu pada perhitungan R
Student, sedangkan pada orange
data mining kedua jenis outlier ini dapat langsung dikeluarkan dengan mengaplikasikan widget outlier.
Referensi
Adair, A. and McGreal,S. (1988) The
Application of Multiple Regression Analysis in Property Valuation,
Journal Valuation, Vol.6 No.1, pp. 57-67.
Bagusco Bagusco Regresi Linear-
Pengantar
Brostrom, O. and Larson, M. (2015) Regression Analysis
as a valuation model: A case study of North American and European construction
industry mergers and acquisitions, Royal Institute of Technology,
School of Engineering Sciences.
Data Tab Regression Analysis Full
Course
Gujarati. D.,N and Porter. D.,C, (2012) Dasar-dasar
Ekonometrika.
Jordan. D.,T., (2007) The
Superiority of Regresiion Analysis over Ratio Analysis. The
Superiority of Regression Analysis over Ratio Analysis - New York Business
Valuation (nybusinessvaluation.com)
Luhst. K. M. (1997) Real Estate
Valuation, Principle and Aplication, Times Mirror Higher Education
Group. Inc. Company.
Appraisal Institute, The Appraisal
of Real Estate 14th Edition, (2013) 200 W. Madison • Suite
1500 • Chicago, IL 60606.
| Disclaimer |
|---|
| Tulisan ini adalah pendapat pribadi dan tidak mencerminkan kebijakan institusi di mana penulis bekerja. |
