Rabu, 22 Juni 2022 | 25662 kali




CRISP DM
Suatu data analisis tidak pernah hadir
dari proses sesaat, namun dari proses matang yang di guide oleh standard
yang tinggi. Statement penulis di atas sangat terbuka untuk
diperdebatkan namun untuk bagian standard dari pernyataan tersebut penulis
yakin semua pihak akan sepakat. Hal inilah yang memotivasi penulis dalam
artikel ini menyampaikan CRISP DM sebagai salah satu standard dalam data
mining.
CRISP DM atau lengkapnya disebut The CRoss Industry Standard Process for Data
Mining merupakan standard yang dikembangkan sejak tahun 1996 di Eropa.
CRISP DM terdiri dari 6 tahap yang mana 3 tahap paling awal berdasarkan
pengalaman penulis dapat Non Mutually Exclusive. Berikut
disajikan keenam tahapan CRISP DM tersebut dalam skema dibawah ini:
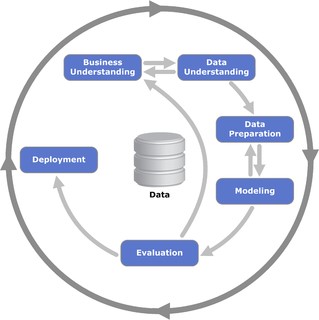
Sumber
Gambar: Wikipedia
CRISP DM bukan merupakan satu-satunya
standard dalam data mining namun merupakan yang terpopuler saat ini. Berdasarkan
hasil pooling datascience-pm, CRISP DM Digunakan 2 sampai dengan 3 kali
lebih banyak dari 4 teratas standard yang paling banyak digunakan.
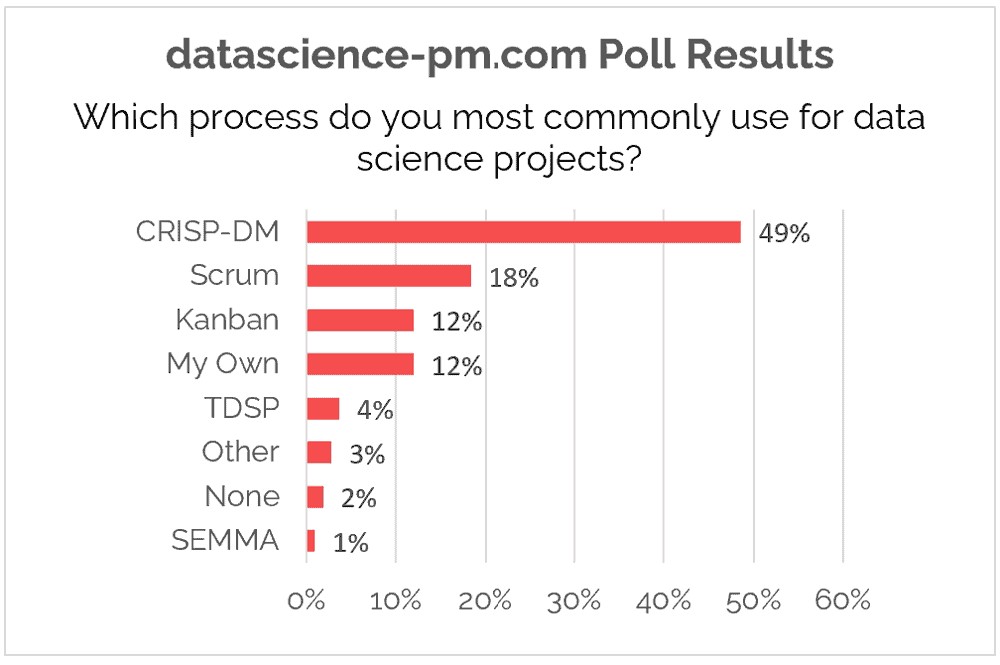
Sumber:
https://www.datascience-pm.com/crisp-dm-2
BUSINESS
UNDERSTANDING
Tahap pertama dari CRISP DM adalah
Business Understanding yang merupakan tahap dimana Business problem
didefinisikan dengan sederhana dan tepat. Meskipun terkesan sederhana pada hakikatnya tahapan
ini memerlukan penguasaan pada dua bagian yang berbeda yaitu pemahaman terhadap
business process termasuk regulasi yang mengaturnya dan pemahaman terhadap cara
pengolahannya.
Konsekuensi dari paragraph di atas
adalah bahwa pemilik business process perlu memahami proses pengolahan data and
vice versa. Tahapan ini sebaiknya juga dilakukan melalui focus group
discussion dengan para pelaku pasar dan studi literatur yang lengkap.
Menggunakan benchmark dari riset di negara lain adalah jalan yang dapat
ditempuh untuk mempercepat tahapan ini sekaligus meningkatkan akuntabilitas,
namun umumnya setiap project adalah unik sehingga terjadi variasi atau
modifikasi sangat dimungkinkan.
Bisnis problem secara spesifik dapat
disebut sebagai gap antara harapan dan realitas dimana data mining akan
menjadi jembatan penghubungnya. Sebagai contoh disajikan pada paragraph di
bawah ini yang diambil dari paper penulis yang berjudul: The Identification
Of Risk And The Determination Of The Choice Of The Financing Disaster On
Indonesia’s State-owned Building In Earthquake- Prone Areas, 2016 sebagai
berikut:
“Kerusakan
bangunan dan infrastruktur akibat gempa bumi di Indonesia mencapai 2 sampai
dengan 4 Milyar Dolar pada setiap gempa. Hal ini menginisiasi diambilnya
Langkah aktif dalam penanggulangan bencana melalui undang-undang Nomor 24 tahun
2007 tentang Penanggulangan bencana yang salah satunya adalah asuransi bencana.
Namun tentu diperlukan panduan dalam mengalokasikan premi asuransi terhadap
bangunan yang tepat mengingat asset negara berupa bangunan dan infrastruktur
sangat banyak dan tersebar baik di daerah rawan gempa mupun tidak. Hal ini
memotivasi kami untuk menemukan cara guna menentukan prioritas asset negara
yang perlu dilindungi dengan asuransi
bencana”.
DATA UNDERSTANDING
Data Understanding merupakan proses
dimana kita mempertemukan antara data apa yang kita miliki dan data apa yang
kita seharusnya perlukan. Bisa jadi suatu project data analisis berawal
dari penemuan data-data yang telah ada yang kemudian mengarahkan analist untuk
menggali knowledge yang ada pada kumpulan data tersebut. Jenis data akan
sangat menentukan jenis algoritma dan tujuan dari data mining yang ingin
dicapai
Pada tahapan ini data analist perlu
menguasai pemahaman terhadap jenis data kuantitatif dan data kualitatif sebagai
berikut:
|
Jenis Data |
Deskripsi |
Hal yang perlu diperhatikan |
Catatan bagi data analist |
|
Nominal |
data yang berasal dari
proses kategorisasi atau klasifikasi |
·
Posisi data setara untuk
setiap subtype. ·
Hanya untuk memberikan
label pada variable ·
lebih tepat menggunakan kode
biner Contoh misalkan terdapat 4 tipe peruntukan lahan maka
digunakan kode seperti ini:
Komersial
1 0 0 Residensial
0 1 0 Perkantoran 0
0 1 Campuran 0
0 0
·
Tidak bisa dilakukan
operasi matematika |
•
Penggunaan
jenis data ini untuk Data mining dengan tujuan prediction dan forecasting
mengacu pada aturan bahwa Jumlah variabel biner harus kurang
1 dari jumlah kategori yang akan dikuantitatifkan (Gujarati dan Porter 2010; 358). •
Sangat baik untuk data mining dengan tujuan asosiasi
dan klasifikasi yang menggunakan jenis data categorical (tidak dinyatakan
dalam angka)
|
|
Ordinal |
data yang berasal dari
proses kategorisasi atau klasifikasi namun diantara data tersebut terdapat hubungan (misalnya
hubungan bertingkat) |
·
Posisi data untuk setiap
subtype tidak setara namun tidak diketahui berapa jarak antar subtype ·
Memiliki urutan dan tidak
memiliki nilai Nol, contoh posisi tanah terhadap elevasi jalan dinyatakan
sebagai berikut: Lebih tinggi 3 Sejajar
2 Lebih rendah 1
· Tidak bisa dilakukan operasi matematika |
Apabila
menggunakan Algoritma Konstanta Nearest Neigborhood, perlu disadari
bahwa jarak antara sub type tidak diketahui artinya hubungan antar dua objek dengan
dengan perbedaan kode 3 dan 2 adalah sama dengan hubungan antara dua objek
dengan kode 2 dan 1. |
|
Interval |
Data interval adalah data
yang diperoleh dengan cara pengukuran namun tidak ada titik nol yang absolut |
· Tidak memiliki nilai Nol
absolut sebagai contoh data pertumbuhan ekonomi dimana terdapat nilai negatif · Bisa dilakukan operasi
matematika terbatas |
Perlu
kehati-hatian dalam menggunakan Konstanta Nearest Neigborhood karena tanda
plus dan minus untuk angka yang sama tidak berbeda contoh: negara
dengan tingkat pertumbuhan positif 2 dan negara dengan tingkat pertumbuhan
minus 2 akan terkumpul dalam kelompok yang sama. |
|
Rasio |
data yang diperoleh dengan
cara pengukuran, dimana jarak dua titik pada skala sudah diketahui, dan
mempunyai titik nol yang absolut |
· Merupakan peringkat
teratas dari semua jenis data · Bisa dilakukan operasi
matematika |
Tepat
untuk digunakan pada data mining dengan algoritma yang berdasar pada semua
jenis operasi matematika. |
DATA
PREPARATION
Proses data preparasi merupakan proses
data treatment menuju model berkualitas yang berguna. Tahapan ini
adalah yang paling menguras resources dari tim analisis. Model yang baik
dan akurat berawal dari data preparasi yang baik. Beberapa hal yang umum
dilakukan pada tahapan ini adalah:
1.
Melakukan
pengecekan kembali pada kebenaran data;
Pengecekan pada data perlu
di desain bertingkat sehingga akuntabilitas terjaga. Pengecekan juga diperlukan
terhadap konsistensi inputing data. System yang baik dalam pengumpulan data
antara lain menggunakan default akan dapat menjaga konsistensi data.
2.
Mengelola
data outlier
Data Outlier perlu dikelola
dengan baik. Data Outlier dapat berupa Univariate Outlier, dan Multivariate
Outlier serta dapat berada pada variable dependent maupun variable independent.
Data Mining untuk tujuan generalisir akan terpengaruh dengan dengan Data
Outlier sehingga perlu dinetralisir. Sebelum melakukan treatment atas data
Outlier alangkah baiknya terlebih dahulu dilakukan pengecekan terhadap
pengambilan dan pengisian data.
3. Memberlakukan data missing dan data inkonsistensi
Perlakuan terhadap data
missing harus match dengan tujuan dari data mining itu sendiri.
Misalkan data missing yang di isi dengan average mungkin masih
dapat diterima untuk tujuan prediction dan forecasting, namun
untuk klastering bisa jadi akan mengarahkan pada kelompok yang kurang tepat.
Sebaliknya menggunakan data yang sering muncul untuk mengisi missing
data untuk multi variable data mining akan berpengaruh pada hasil untuk tujuan prediction
dan forecasting.
MODELING
Model adalah deskripsi atau
knowledge berkualitas yang dibangun oleh system atau process dari kalkulasi dan
prediksi yang berterima. Kata sifat berterima disini mengacu pada
sedikitnya beberapa hal yaitu technically correct dan economically
correct (pada penelitian ekonomi).
Mayoritas praktisi sepakat dengan La
rose (2005) bahwa terdapat 5 (lima) tujuan utama dalam data Mining yaitu: Estimasi,
Prediksi/Peramalan, Klasifikasi, Klastering, Asosiasi. Lebih dari satu peran
dapat dikombinasikan untuk mencapai tujuan yang lebih detil. Berdasarkan peran
tersebut menurut pengalaman penulis terdapat beberapa Algoritma yang dapat digunakan
sebagaimana disampaikan pada gambar di bawah ini:
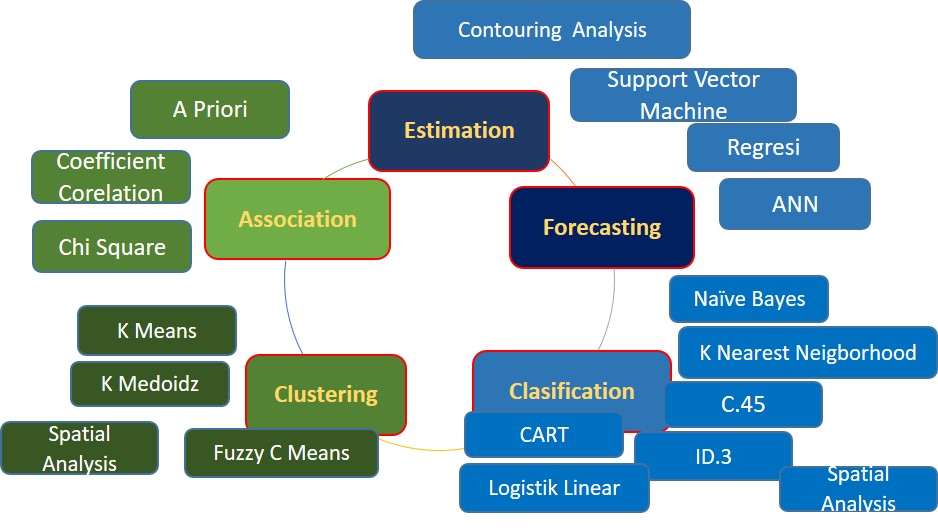
Algoritma pada gambar di atas secara
umum juga terbagi dalam 2 (dua) kelompok, untuk kelompok algoritma berwarna
biru (biru muda s.d biru tua) merupakan Supervised Learning sedangkan
yang berwarna hijau (hijau s.d. hijau tua) merupakan unsupervised learning.
Supervised Learning merupakan algoritma yang memerlukan target atau dependent
variable, sedangkan Unsupervised learning tidak menggunakan target
atau dependent variable. Berikut beberapa kemungkinan pemanfaatan algoritma
data mining dalam manajemen asset disajikan dalam table di bawah ini:
|
Algoritma |
Penggunaan
dalam Aset Manajemen |
|
Estimasi
dan forecasting |
Panduan
dalam Penilaian |
|
Klasifikasi |
Panduan
Menentukan Skema Pemanfaatan |
|
Panduan
Asuransi BMN |
|
|
Klaster |
Panduan
Menentukan Pembanding terdekat dengan Objek Penilaian |
|
Panduan
Menentukan Asset yang dapat dimanfaatkan |
|
|
Assosiasi |
Panduan
Menentukan Calon Peserta Lelang Potensial |
|
Panduan
Management Risiko |
Proses modelling adalah saat paling
menyenangkan dalam proses pengolahan data, karena ide dan inovasi baru sangat
berperan pada tahap ini. Satu data set yang telah di preparasi dengan baik dapat di olah dalam lebih dari satu jenis
algoritma dan dapat memberikan knowledge yang berbeda-beda.
EVALUASI
Evaluasi merupakan tahap validasi
model yang dibentuk berdasarkan parameter-parameter yang relevan. Parameter
tersebut bisa berupa Parameter statistik, Parameter ekonomi dan lain-lain. Parameter statistic misalnya dengan uji asumsi
klasik dan/atau nilai R2, sedangkan parameter ekonomi dapat menggunakan data
testing yang dianggap paling mewakili pasar dan bisa juga menggunakan Teknik willingness
to pay atau willingness to accept.
Data analyst perlu memperhatikan bahwa koefisien
determinasi R² yang tinggi adalah baik namun yang terpenting adalah mengetahui
apakah koefisien regresi yang kita peroleh secara statistik signifikan atau
terdapat indikasi koefisien tersebut berlawanan dari harapan (lihat Damodaran
dan Porter 2009:266) (lihat Insukindro; 1998). Dalam artikel selanjutnya
evaluasi model akan kita bahas lebih lengkap.
DEPLOYMENT
Tahap Deployment adalah saat dimana
para analyst dan engineer mempacking dan menyampaikan proses data analisis yang
telah dilakukan. Beberapa pertimbangan yang semestinya diperhitungkan
adalah visualisasi, kemudahan dari penggunaan model, pemeliharaan model dimasa
yang akan datang, serta payung hukum yang menyertai penggunaan model tersebut. Mengapa
legally permissible adalah faktor yang harus diperhatikan, karena
modelling akan menuntun kearah pengambilan keputusan yang sarat akan
rambu-rambu peraturan. Berdasarkan hasil diskusi pada saat mengikuti Digital
Leadership Course yang digelar oleh Pertamina Training Center sekitar tahun
2019 yaitu: Hasil data mining seringkali melampaui produk hukum yang berlaku
saat itu, sehingga penggunaannya seringkali memerlukan penyesuaian.
Tulisan ini didasari atas pengalaman
dan referensi terkait Data Mining.
Ditulis oleh: Helvita Dorojatun (Kepala KPKNL Mamuju)
(Tulisan ini merupakan bagian dari seri Artikel DATA DRIVEN DECISION MAKING, KPKNL MAMUJU untuk KEMENKEU)




